AthenaとQuickSightを試す
参考記事
この記事を多大に参照して、試してみる。
S3へのデータの保管
まずはこちらから鎌倉市の職員給与データをダウンロード。 https://www.city.kamakura.kanagawa.jp/opendata/kyuuyo.html
S3にHive形式のPartitionを区切り、データを格納する
。
DBとTableの作成
Athenaでデータベースとテーブルの作成。
DBの作成
Athenaのクエリで作成。 下記コマンドで一発です。
create database DB_NAME
Tableの作成
DDLを書いて、テーブルを作ります。今回のCSV形式データを見たところ、下記のようなDDLで良さそう。
CREATE EXTERNAL TABLE IF NOT EXISTS emp_salary( no int, level string, salary int, huyou int, tiiki int, jukyo int, tsukin int, tokusyu int, jikangai int, kyujitsu int, yakan int, kanri int, syuku int, kanri_toku int, salary_all int, bonus int, kinben int, salary_year int ) PARTITIONED BY( `year` int) ROW FORMAT DELIMITED FIELDS TERMINATED BY "," STORED AS INPUTFORMAT "org.apache.hadoop.mapred.TextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat" LOCATION 's3://BUCKET_NAME/kamakura' TBLPROPERTIES ( "has_encrypted_data"="false", "skip.header.line.count" = "1", "serialization.encoding"="SJIS" )
Tableの動作確認
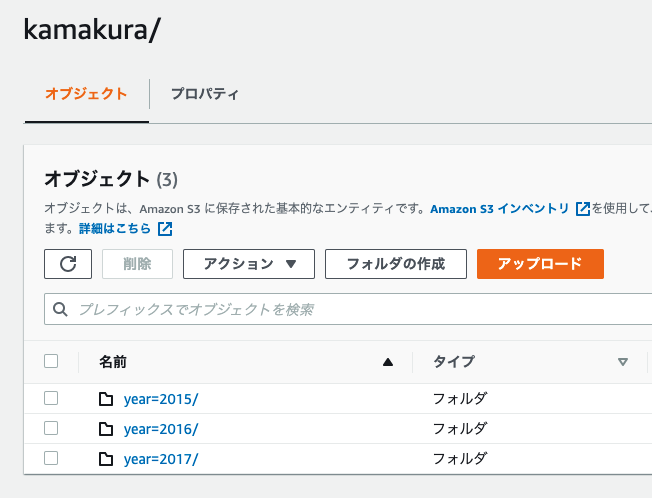
- パーティションの追加
MSCK REPAIR TABLE emp_salary
- SELECTでデータ確認
SELECT * FROM "sample_db"."emp_salary" limit 10;
QuickSight
QuickSightのアカウントを作成する。
先ほどデータを格納したS3バケットへのアクセスだけ注意しつつ、作成する。
分析の追加
「新しい分析→新しいデータセット」をクリックし、新規データソースとしてAthenaを選択する。
データソース名は任意につける。
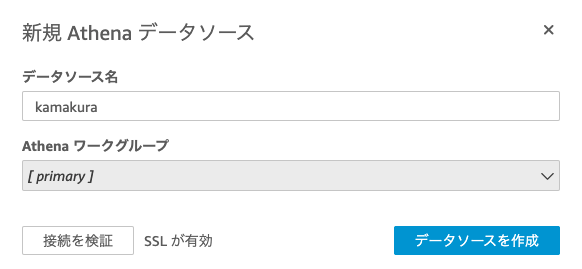
すでに作成したテーブルを選択する。

データクエリを直接実行を選択し、Visualizeを実行。
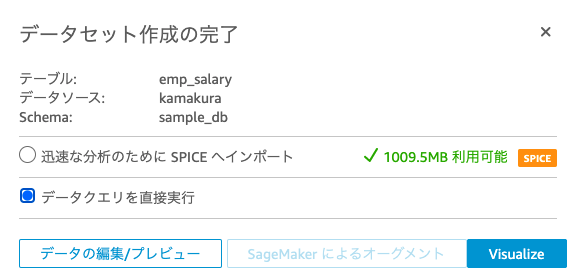
SPICEは高速なインメモリ計算エンジンで、高速なダッシュボードの提供だったり高いパフォーマンスがほしいときに使える。詳細はこちらを参照。
Visualize
bonus vs salary
これは参考サイトの元記事そのままですが、可視化してみる。
月収30万円ほどのところでギャップがある。またボーナスと月収はおおむね正相関がある。

bonus vs level
平均ボーナス額と職位の関係を可視化する。
棒グラフに設定をして、x軸にlevel、y軸にbonusを設定。
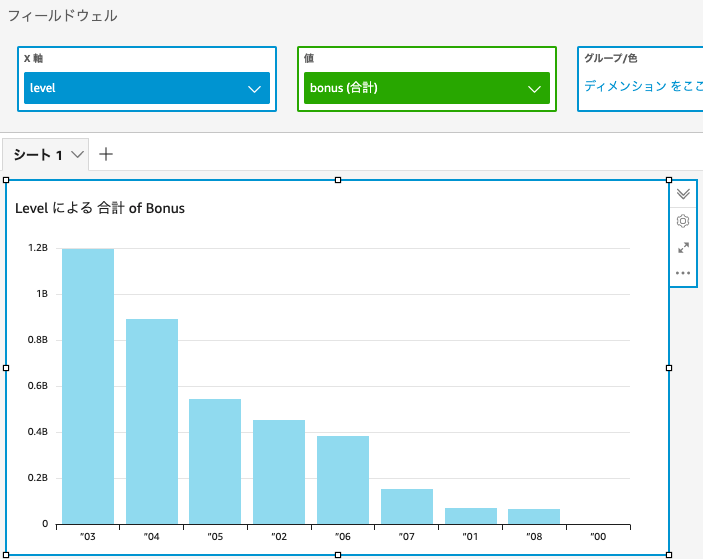
このままだと合計額となっており、数の多い職位レベル3が最大となってしまうので、平均に切り替え。
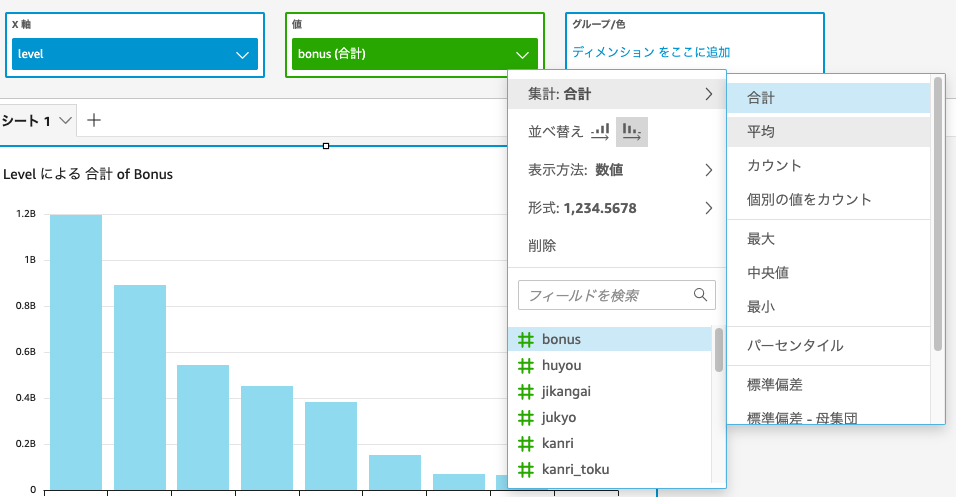
さらにx軸の並び替えをすることで、職位順に見ることが可能。
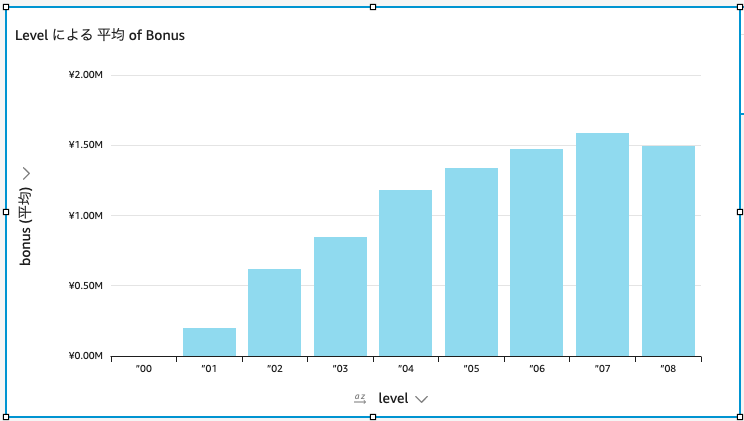
少し体裁を整えると、見やすくなった。
まとめ
- S3にある程度構造化されたデータを入れて、Athenaでテーブルを作っておくことで、手軽に可視化をすることが可能。
- 他のサービスとの連携も試してみたい。