SageMaker CanvasとRandomForestとCatBoostで性能を簡易に比較してみた。
はじめに
SageMaker Canvasは、SageMakerのAutoMLのようなもので、構造化データを突っ込んで、モデル作成!って押すとモデルが作成される。 今回はその性能を自分の目で確かめてみようと思う。 ちなみにタイトルに性能比較とかたいそうなことが書いてあるけど、ちょっと試してみただけです。 詳細な条件とか、実験計画とかはなしに、気楽な実験です。
DataSet
Allstate Claims Severityデータセットを利用。 Allstate Claims Severity | Kaggle
保険の請求額を推測するモデルを構築すれば良い。簡単に言えば、回帰問題。 カテゴリ変数が多いのでそれをどう扱うかが見せ所なのかも?
モデル作成
SageMaker Canvas
Training
難しいことはひとつもなくて、S3に置いてあるデータを選んで、モデル作成!って押すだけ。
モデル作成中はこんな画面が出てくる。
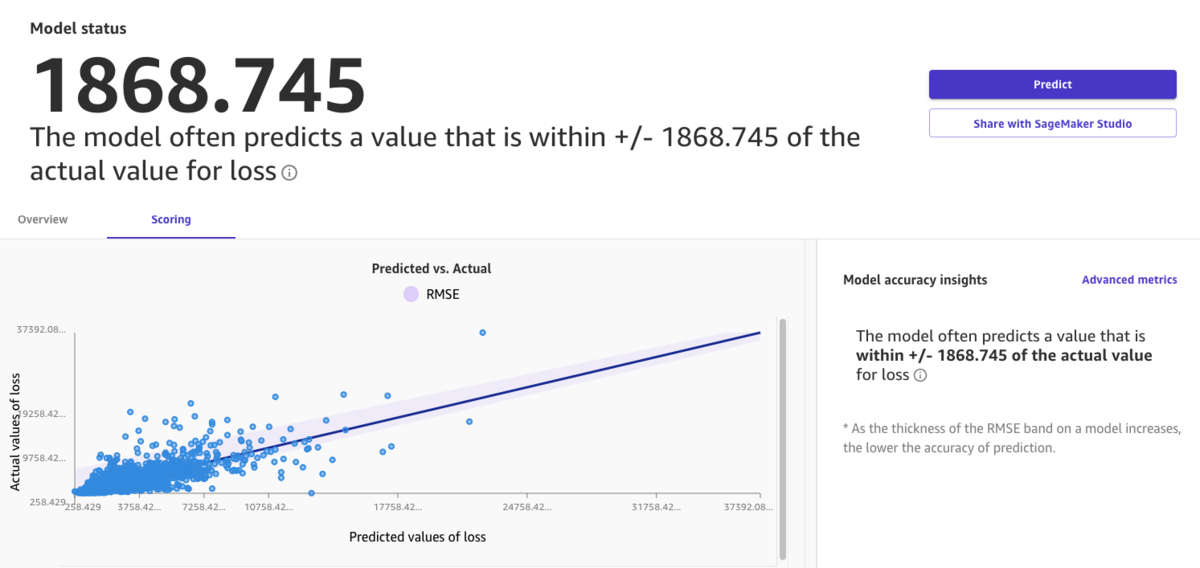
学習が終わると、こういう画面が出る。
学習データでのRMSEが1868.745。
Inference
testデータにも推論をかけて、kaggleに投稿をしてみる。
testデータに推論をかけるには、あらかじめtestデータをS3などに置き、Canvas上にimportしておく。
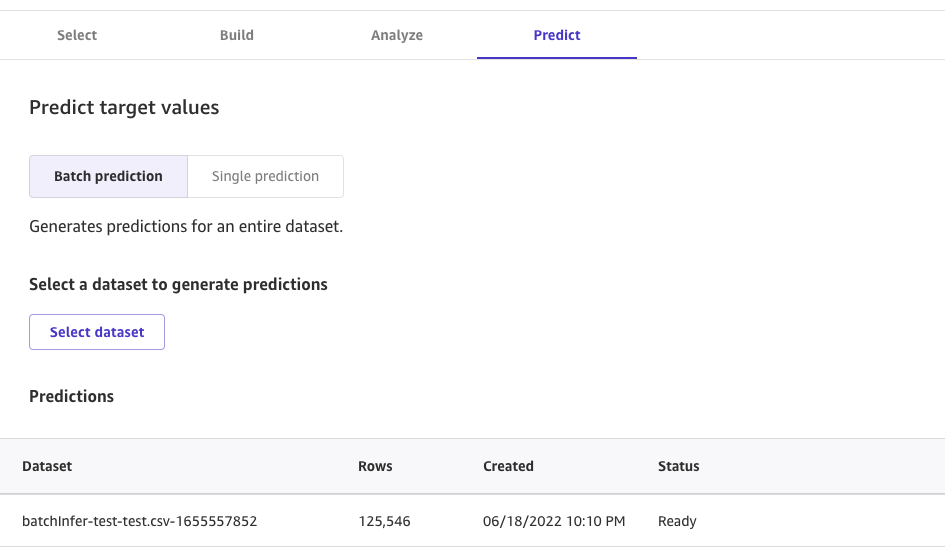
Canvasのpredict画面から、データを選ぶだけで、Batch Inferenceが可能である。
推論が終わると下記のような画面が表示され、結果をダウンロードできる。
Evaluation
結果をkaggleに投稿してみる。
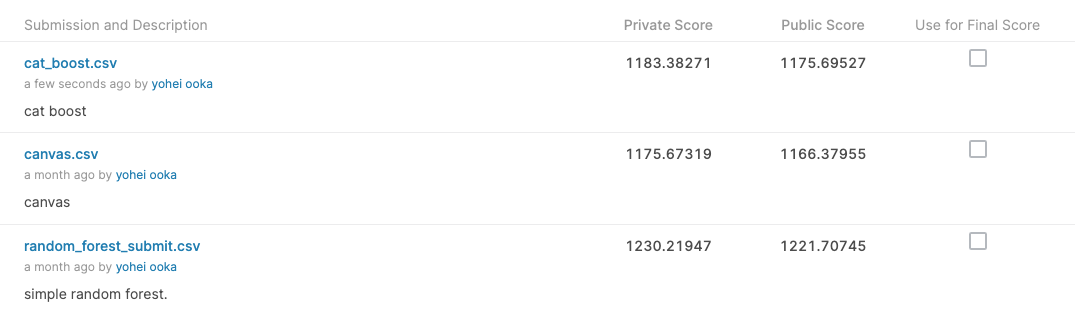
Private Score: 1175.67319 Public Score: 1166.37955
ランキングに照らし合わせてみると、だいたい2000位くらい。 フルオートにしてはまぁそこそこうまくいってるような、それなりなような。
RandomForest
手元で簡単なモデルでも学習。 ごく普通にScikit-learnのRandom Forest Regressorで学習、推論。 kaggleに投稿した結果は下記の通り。
Private Score: 1230.21947 Public Score: 1221.70745
さすがにCanvasよりは悪い。ランキングに照らし合わせると、2300位くらい。 どうだろうか・・なんともいえない?
CatBoost
カテゴリ変数がたくさんあるので、CatBoostが強いのではないかと考えてみる。 あまり深く考えず、ごく普通のコードでCatBoostを学習。Canvasに結構肉薄する。
Private Score: 1183.38271 Public Score: 1175.69527
Kaggleのスクショ
ここまでのまとめ画像。
今回の気づき
とりあえずフルオートで作れるし、簡単に試した中では最も性能がよかったので、Canvas結構いいんじゃないかと。 全くコードを書かずにそれなりに性能が出ている。
ただしリーダーボードの上位ほど出るわけでもないし、CatBoostはCrossValidationすらしていないので、自身でコードを書けるならもっと改善できそう。 逆にCanvasを改善する方法は今のところデータを増やすくらいしかないと思っているので、コードを書けるなら無理して使わなくてもいいかもしれない。
ただ、初期検討でとりあえずこのデータでも性能出そう、とかそういう占いには結構便利かも。 なんたって数クリックでモデルが作れるわけだし。
今回はカテゴリ変数が多い問題だったけど他の問題とかも少し試してみたくなる。 とりあえず今回はここまで。
GStreamerでmac bookのカメラをKinesis Video Streamに流す
全体アーキテクチャ
全体像はこんな感じ。2段構え。
 MacでKVSのSDKをbuildするのが面倒なのでDockerで済ます。
Cloud9を利用することもできるけど、カメラがないので、ローカルのMacで試すことにした。
MacでKVSのSDKをbuildするのが面倒なのでDockerで済ます。
Cloud9を利用することもできるけど、カメラがないので、ローカルのMacで試すことにした。
手順
とりあえず、試したいAWSアカウントを用意しておく。
Dockerイメージのダウンロード
基本的な手順はここに従う。 ただし、ドキュメントのdocker loginのコマンドは古いので注意。下記のようなコマンドを叩けば良い。
aws ecr get-login-password --region us-west-2 | docker login -u AWS --password-stdin https://546150905175.dkr.ecr.us-west-2.amazonaws.com sudo docker pull 546150905175.dkr.ecr.us-west-2.amazonaws.com/kinesis-video-producer-sdk-cpp-amazon-linux:latest
注意として、プロファイルのdefault regionをap-northeast-1にしていると、エラーが出るので、--regionオプションを忘れないこと。
コンテナ立ち上げ
普通にImageをRunしてあげれば良い。 IoTCoreを使って認証したい場合は、認証用の鍵などを入れたファイルをコンテナ内に用意する必要があるので、マウントするなり、ファイルをコピーするカスタムコンテナを用意する必要がある。今回は-vオプションで、ボリュームマウントをしておく。(その中にIoTCoreの証明書などを入れておく。)
sudo docker run -it -v <LOCAL_DIR>:<CONTAINER_DIR> --network="host" 546150905175.dkr.ecr.us-west-2.amazonaws.com/kinesis-video-producer-sdk-cpp-amazon-linux /bin/bash
Macローカル側でやること
すでにKVS SDKの動く状態のコンテナが立ち上がっているので、そこにめがけてカメラストリームを流し込む必要がある。
Gstreamerのインストール
Homebrewで一発。
brew install gstreamer gst-plugins-base gst-plugins-good gst-plugins-bad
gst-launchの実行
下記のようなコマンドでgstreamerを叩く。 宛先はtcpserversinkで、127.0.0.1向け。
$ gst-launch-1.0 autovideosrc ! videoconvert ! video/x-raw,width=1280,height=720 ! vtenc_h264_hw allow-frame-reordering=FALSE realtime=TRUE max-keyframe-interval=45 bitrate=512 ! gdppay ! tcpserversink host=127.0.0.1 パイプラインを一時停止 (PAUSED) にしています... Pipeline is live and does not need PREROLL ... Pipeline is PREROLLED ... パイプラインを再生中 (PLAYING) にしています... New clock: GstSystemClock Redistribute latency... WARNING: from element /GstPipeline:pipeline0/GstTCPServerSink:tcpserversink0: Pipeline construction is invalid, please add queues. 追加のデバッグ情報: ../libs/gst/base/gstbasesink.c(1258): gst_base_sink_query_latency (): /GstPipeline:pipeline0/GstTCPServerSink:tcpserversink0: Not enough buffering available for the processing deadline of 0:00:00.020000000, add enough queues to buffer 0:00:00.020000000 additional data. Shortening processing latency to 0:00:00.000000000. 0:00:13.6 / 99:99:99.
Dockerコンテナ内でやること
gst-launchの実行
gst-launch-1.0 -v tcpclientsrc host=host.docker.internal ! gdpdepay ! video/x-h264, format=avc,alignment=au ! h264parse ! kvssink stream-name=<STREAM_NAME> iot-certificate=$KVS_IOT_CERTIFICATE aws-region=$KVS_AWS_DEFAULT_REGION
kvssinkで、streamの名前を指定している。
環境変数としてIoTのCertificateとリージョンを渡している。iot-certificateは、IoTCoreでの認証を行う場合の引数。実際の中身は、下記のようになっている。
export KVS_IOT_CERTIFICATE="iot-certificate,endpoint=<KVS_ENDPOINT>,cert-path=<IoT_CERT>,key-path=<IoT_KEY>,ca-path=<IoT_CA>,role-aliases=<IoT_ROLE_ALIAS>"
以上を実行して、マネジメントコンソールなどでKinesis Video Streamのメディア再生を確認すれば、Macのウェブカメラ画像が流れているはず。
Sagemaker notebook instanceでユーザ環境を作る
いつ使う
SageMakerでnotebook instanceのkernelを選択したときに、python3.6、ちょっと古いなぁ、python3.8とか使いたいなぁと思った人向け。
Notebookでterminalを開く
下記コマンドを利用して、conda createする。
例えばpython3.8で作る場合はこんな感じ。
これはEBSボリュームにPython環境を作っており、EC2の再起動で消えないようにするためである。
conda create --prefix /home/ec2-user/SageMaker/kernels/<USER_ENV> python=3.8 ipykernel source activate /home/ec2-user/SageMaker/kernels/<USER_ENV> python -m ipykernel install --user --name <USER_ENV> --display-name <USER_ENV> conda deactivate
このコマンドを叩いたあとに、JupyterのKernelに自身の環境が追加されたことを確認する。
永続化
Sagemakerのインスタンスの再起動で環境の登録が消えてしまうので、起動時に追加されるようにライフサイクル設定を実行する。
一度インスタンスを停止して、Sagemakerのマネコンから、「ライフサイクル設定」を選択。
スクリプトとして下記を入力する。
#!/bin/bash
sudo -u ec2-user -i <<'EOF'
if [ -d "/home/ec2-user/SageMaker/kernels" ]; then
for env in /home/ec2-user/SageMaker/kernels/*; do
source activate $env
python -m ipykernel install --user --name $(basename "$env") --display-name "$(basename "$env")"
conda deactivate
done
fi
EOF
ノートブックインスタンスの「設定の更新」から、作成したライフサイクル設定を選択すればOK。
次回起動時に登録されているかを確認しておわり。
conda環境の整え方
jupyterの画面で! conda installとかやるのはめんどくさいので、基本的にはTerminalを起動して上記で紹介したコマンド
source activate /home/ec2-user/SageMaker/kernels/<USER_ENV> conda install ****
という感じでやるとラク。
AthenaとQuickSightを試す
参考記事
この記事を多大に参照して、試してみる。
S3へのデータの保管
まずはこちらから鎌倉市の職員給与データをダウンロード。 https://www.city.kamakura.kanagawa.jp/opendata/kyuuyo.html
S3にHive形式のPartitionを区切り、データを格納する
。
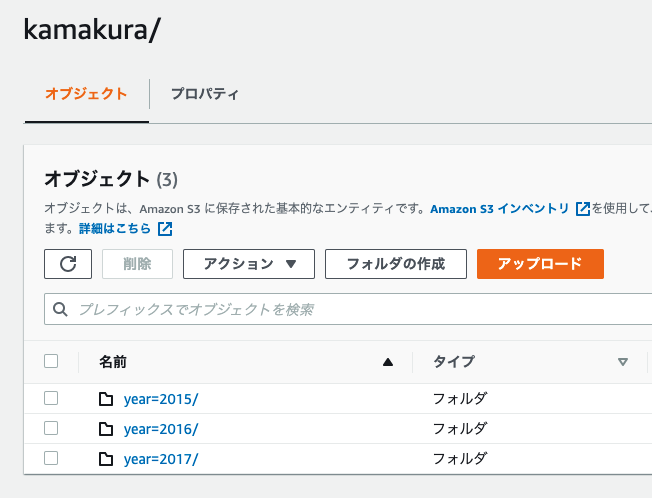
DBとTableの作成
Athenaでデータベースとテーブルの作成。
DBの作成
Athenaのクエリで作成。 下記コマンドで一発です。
create database DB_NAME
Tableの作成
DDLを書いて、テーブルを作ります。今回のCSV形式データを見たところ、下記のようなDDLで良さそう。
CREATE EXTERNAL TABLE IF NOT EXISTS emp_salary( no int, level string, salary int, huyou int, tiiki int, jukyo int, tsukin int, tokusyu int, jikangai int, kyujitsu int, yakan int, kanri int, syuku int, kanri_toku int, salary_all int, bonus int, kinben int, salary_year int ) PARTITIONED BY( `year` int) ROW FORMAT DELIMITED FIELDS TERMINATED BY "," STORED AS INPUTFORMAT "org.apache.hadoop.mapred.TextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat" LOCATION 's3://BUCKET_NAME/kamakura' TBLPROPERTIES ( "has_encrypted_data"="false", "skip.header.line.count" = "1", "serialization.encoding"="SJIS" )
Tableの動作確認
- パーティションの追加
MSCK REPAIR TABLE emp_salary
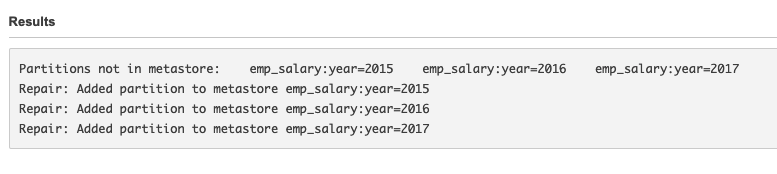
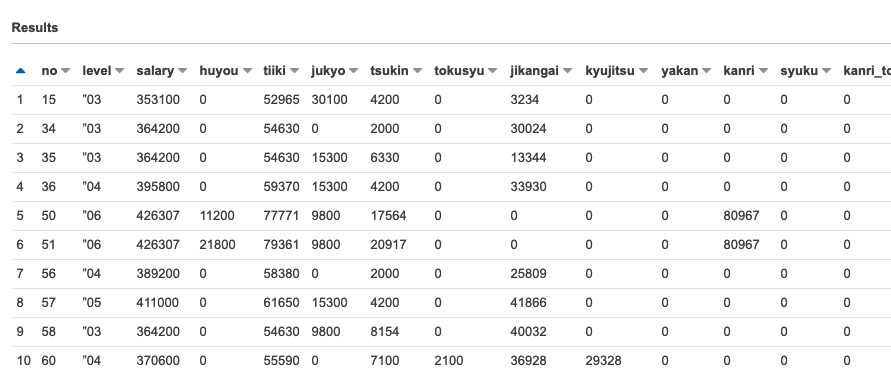
- SELECTでデータ確認
SELECT * FROM "sample_db"."emp_salary" limit 10;
QuickSight
QuickSightのアカウントを作成する。
先ほどデータを格納したS3バケットへのアクセスだけ注意しつつ、作成する。
分析の追加
「新しい分析→新しいデータセット」をクリックし、新規データソースとしてAthenaを選択する。
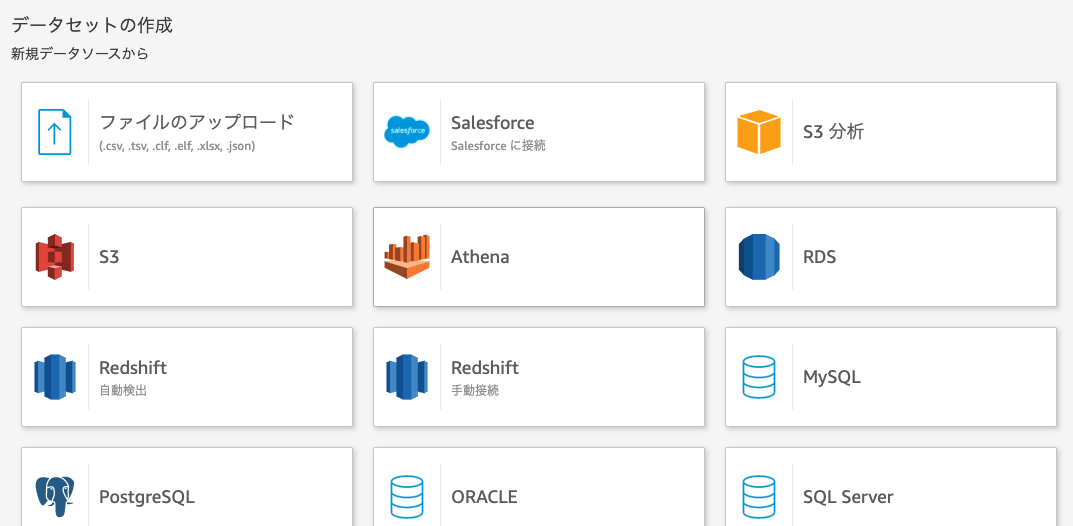
データソース名は任意につける。
すでに作成したテーブルを選択する。

データクエリを直接実行を選択し、Visualizeを実行。
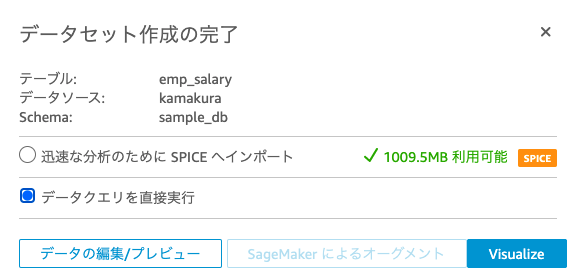
SPICEは高速なインメモリ計算エンジンで、高速なダッシュボードの提供だったり高いパフォーマンスがほしいときに使える。詳細はこちらを参照。
Visualize
bonus vs salary
これは参考サイトの元記事そのままですが、可視化してみる。
月収30万円ほどのところでギャップがある。またボーナスと月収はおおむね正相関がある。

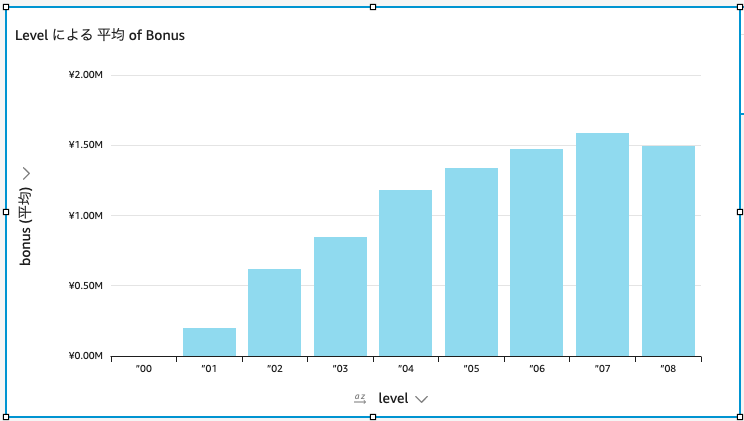
bonus vs level
平均ボーナス額と職位の関係を可視化する。
棒グラフに設定をして、x軸にlevel、y軸にbonusを設定。
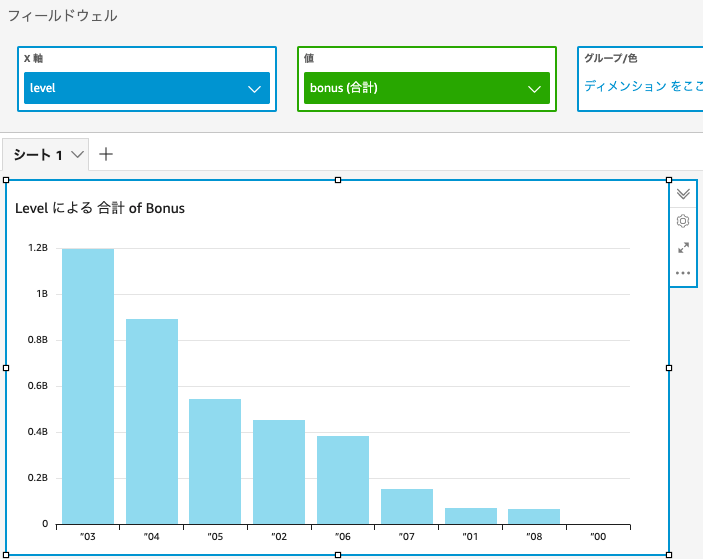
このままだと合計額となっており、数の多い職位レベル3が最大となってしまうので、平均に切り替え。
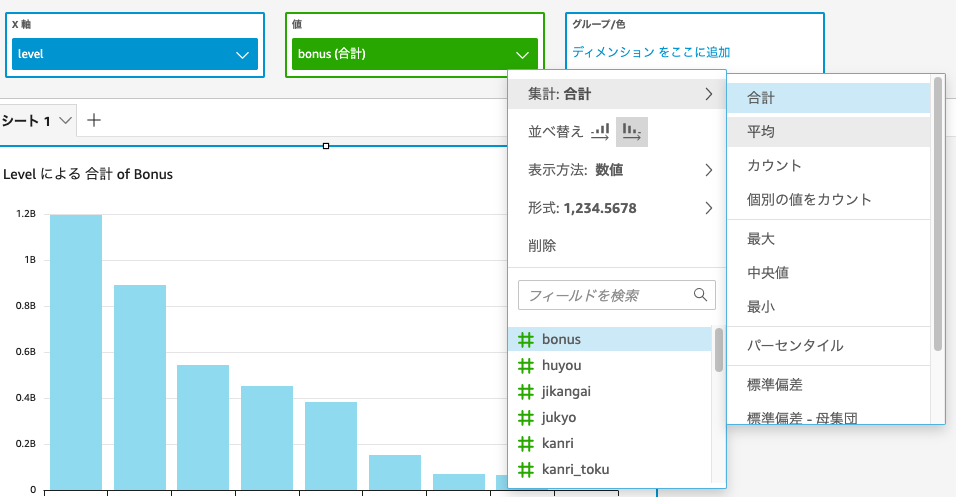
さらにx軸の並び替えをすることで、職位順に見ることが可能。
少し体裁を整えると、見やすくなった。
まとめ
- S3にある程度構造化されたデータを入れて、Athenaでテーブルを作っておくことで、手軽に可視化をすることが可能。
- 他のサービスとの連携も試してみたい。
【Tips】Docker permissionエラー
エラー内容
このエラー↓が出たときの対処
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock:
対処方法
ユーザーにdockerの権限がないので、与える必要がある。 そのために、dockerのユーザーグループに自身を追加し、次にdocker.sock に書き込み権限を付与する。 流れは下記の通り。
sudo gpasswd -a $(whoami) docker sudo chgrp docker /var/run/docker.sock sudo service docker restart
CodePipelineとPytestで自動テスト
別にPythonじゃなくてCでもC++でもいいんだけど、機械学習屋さんとしてはPythonに慣れ親しんでいるので、その例でトライ。 HelloWorldで書いても良かったけど、せっかくなのでgit pushすると、自動でPytestが動くようなもの。
CodeCommitとPytestとbuildファイルの準備
手元のgit環境の準備
CodeCommitにリポジトリを作成して、自在にgit clone, git pushできる環境を作っておく。 EC2にIAMロールを設定してやるのが一番シンプル。
適切なPythonコードの準備
ディレクトリ構成はこんな感じ。今回はtest_1.pyじゃなくて、test_str.pyという名前にする。

test_str.pyは、すごく簡単なテストを置く。
def test_str(): assert 'a' == 'a' assert 'b' == 'b'
buildspec.yamlファイルの準備
こんなファイルを準備。
version: 0.2 phases: install: runtime-versions: python: 3.8 commands: - pip3 install pytest build: commands: - echo test - pytest --junit-xml=reports/unittest_results.xml reports: pytest_reports: files: - unittest_results.xml base-directory: reports file-format: JUNITXML
- python3.8を使いますという宣言
- テストをしたいのでpytestをインストール
- pytestコマンドの実行 オプションとして、レポートファイルを出力
ちなみにpytestはフォーマットに従っていれば、ディレクトリなどを指定しなくても自動でテストファイルを探してテストしてくれる。
buildspec.yamlは下記のようなディレクトリ構成位置に置く。

CodeBuildの準備
ビルドプロジェクトの作成
マネジメントコンソールから、下記の設定で作っていく。
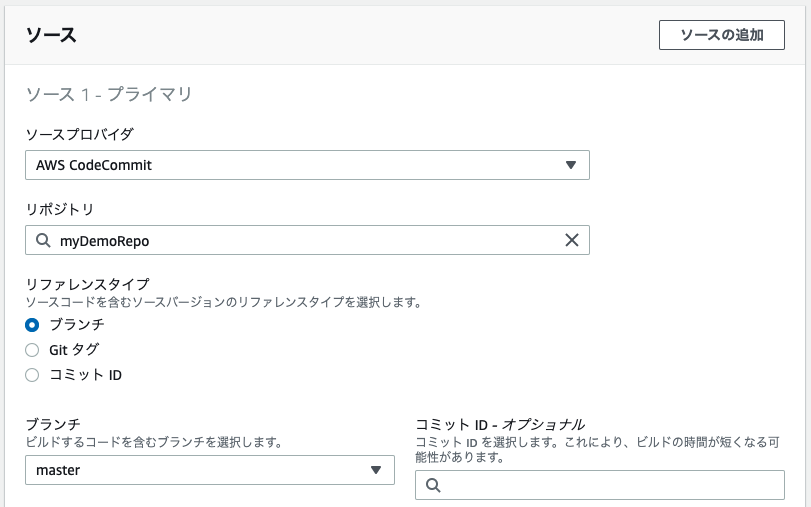
環境についてはpythonと機械学習ならUbuntuを選んでおくと良い気がする。確信はない。
(本来は環境がちゃんと用意されたDockerイメージを用意したほうが良いと思う。それは今度勉強する予定。)
ランタイムはStandardでとりあえず動く。

Buildspecは前項で作ったファイルを使うので、buildspecファイルを使用する。を選択。 これでビルドプロジェクトを作成。
CodePipelineの準備
プロジェクト名を任意で付与して作る。
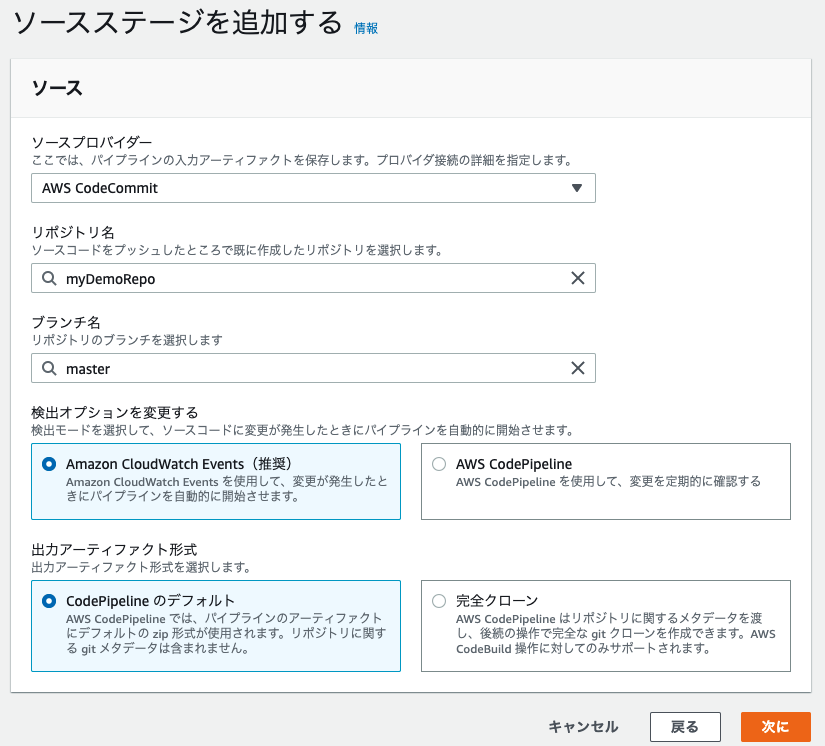
ソースステージ
ビルドステージ
- プロバイダー:AWS CodeBuild
- リージョン:アジア・パシフィック(東京)
- プロジェクト名:CodeBuildの準備で作成したプロジェクト名
残りはデフォルト。

デプロイステージ
今回は自動テストまでをスコープとするので、導入段階をスキップをクリック。 以上でパイプラインを作成できる。
自動テスト
恐らくパイプラインを作っただけで、1回目のパイプラインが流れる、と思う。 テストはエラーが起きないようなテストなので、成功するはず。
以降、コードをPUSHするたびに自動的にパイプラインが流れ、自動テストが実行される。 実行結果はCodeBuildのビルド履歴やレポート履歴で見ることが可能。
IAMロールを使ってCodeCommitからクローンする
EC2を使って、CodeCommitからリポジトリをクローンしたい場合、 credential情報を使わずに、IAMロールを使うことが可能。
IAMロールの設定
EC2にCodeCommitのポリシーをつける。
とりあえずFullAccessを付与。ReadOnlyなどは適宜設定。

gitの設定
gitのcredentialのhelperとして、awsコマンドを用いるように設定する。
$ git config --global credential.helper '!aws --region ap-northeast-1 codecommit credential-helper $@' $ git config --global credential.UseHttpPath true
cloneする
SSHでEC2に入った状態で、下記コマンドで普通に取得可能
$ git clone http://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/REPOSITORY NAME
EC2からcloneするなら、アクセスキーなどを使用しないほうが圧倒的にスマート。